mirror of
https://gitlab.com/game-loader/hugo.git
synced 2025-04-20 05:52:07 +08:00
78 lines
8.7 KiB
Markdown
78 lines
8.7 KiB
Markdown
---
|
||
title: Nvidia BaM SSD作为GPU主存
|
||
author: Logic
|
||
date: 2023-12-24
|
||
categories: ["论文"]
|
||
tags: []
|
||
draft: false
|
||
---
|
||
|
||
# BaM论文阅读 使用SSD作为GPU的主存----Nvidia
|
||
|
||
## 研究背景
|
||
|
||
随着推荐系统, 图神经网络和深度学习等相关应用的兴起, GPU需要对存储的数据集进行大规模的访问用于计算. 将数据载入显存并从显存读取是最高效的方式. 尽管GPU的显存在过去几年间已经有了大幅度的提升, 但也仅有80GB. 而这些应用中的数据集大小可能数百个GB乃至TB级. 不可能将全部数据直接载入显存中. 作者将过去解决data access问题的方法总结为两种.
|
||
|
||
1. CPU-centric approach
|
||
|
||
这种方式的就是通过CPU对数据进行一些预处理如将大规模数据集分片并编排数据, 决定哪一部分数据装入GPU显存中来进行当前的计算任务. 或者通过内存映射文件, 当GPU触发page fault的时候使用CPU的page fault handler来控制传输需要的数据. 这一类型方法的性能显然受制于CPU本身的性能瓶颈, 如CPU相关软件如控制缺页处理的程序性能消耗. 还有CPU-GPU同步造成的性能开销.
|
||
|
||
2. DRAM-only solution
|
||
|
||
这种方式是指最直观的解决显存不足问题的方法, 就是通过某种手段增大显存容量. 一种方式是使用主机内存. 另一种方法是将多个GPU连在一起共享显存, 比如著名的NVLink技术. 这类方式的确十分高效, 但有一个致命问题就是价格昂贵.
|
||
|
||
为了充分利用GPU的高并行能力, 同时获得更高的性价比. Nvidia 提出了让GPU直连SSD, 从存储器中直接获取数据到显存中的思路.
|
||
之前同样由Nvidia提出的GPU Direct Storage (GDS, 下同) 是一个类型的解决方案, 但仍有可以改进的地方, 这篇文章则可以视为对GDS的进一步改进.
|
||
|
||
## 核心架构
|
||
|
||
|
||
|
||
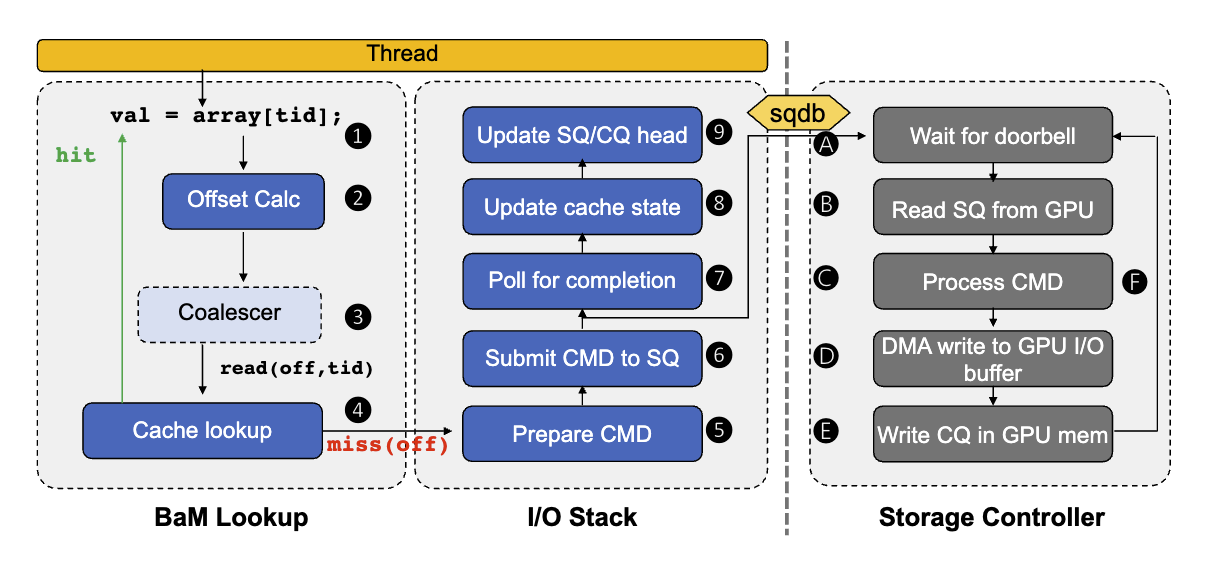
使用bam::array访问数据的的主要过程为. 使用array来决定访问偏移,比如array[2]这种形式2这个下标就决定了访问偏移. 同一个warp中的线程如果访问的是同一个偏移的数据, 这些线程就可以进行联合访问. 派一个代表线程获取偏移处的元数据, 比如cache line的元数据. 如果cache命中, 则直接从显存中取数据, 不命中就要从主存. BaM从SSD中取数据时通过尽量消除多余的主存请求并且允许用户配置应用需要的数据来最大化利用带宽. 从主存取数据时, 线程进入一个I/O栈来准备对SSD发送I/O请求. 线程将请求放入请求队列中. 等待存储控制器将相应的请求的完成信号放在完成队列中.
|
||
|
||
存储控制器一旦收到一个doorbell, 就从SQ(提交队列,submit queue, 下同)中取出一个要求获取数据的信号, 处理数据获取指令, 将数据从SSD传输到GPU显存中. 传输完成后, 在CQ(完成队列, complete queue)中提交一个信号.
|
||
|
||
线程从CQ中发现了完成信号后, 就更新cache状态, 更新SQ/CQ, 然后正常的处理数据.
|
||
|
||
很明显, SQ/CQ的设计是这个架构的核心. 这里我们会有一些疑问, 比如提交到SQ是怎样提交的, 更新SQ/CQ具体是指什么操作. 下面就详细介绍SQ/CQ的设计.
|
||
|
||
## 高吞吐I/O队列设计
|
||
|
||
在现有的存取I/O协议的设计中, 发送doorbell和清理SQ队列中的信号都是序列化操作, 在执行这些操作时进程会进入临界区, 尽管操作很简单, 但这个临界区在高并发场景下仍会大幅影响吞吐量, 提高延迟. BaM采用了一种细粒度的内存同步机制, 使得大量线程可以同时进入SQ, 轮询CQ, 或者标记某个信号已被使用完.
|
||
|
||
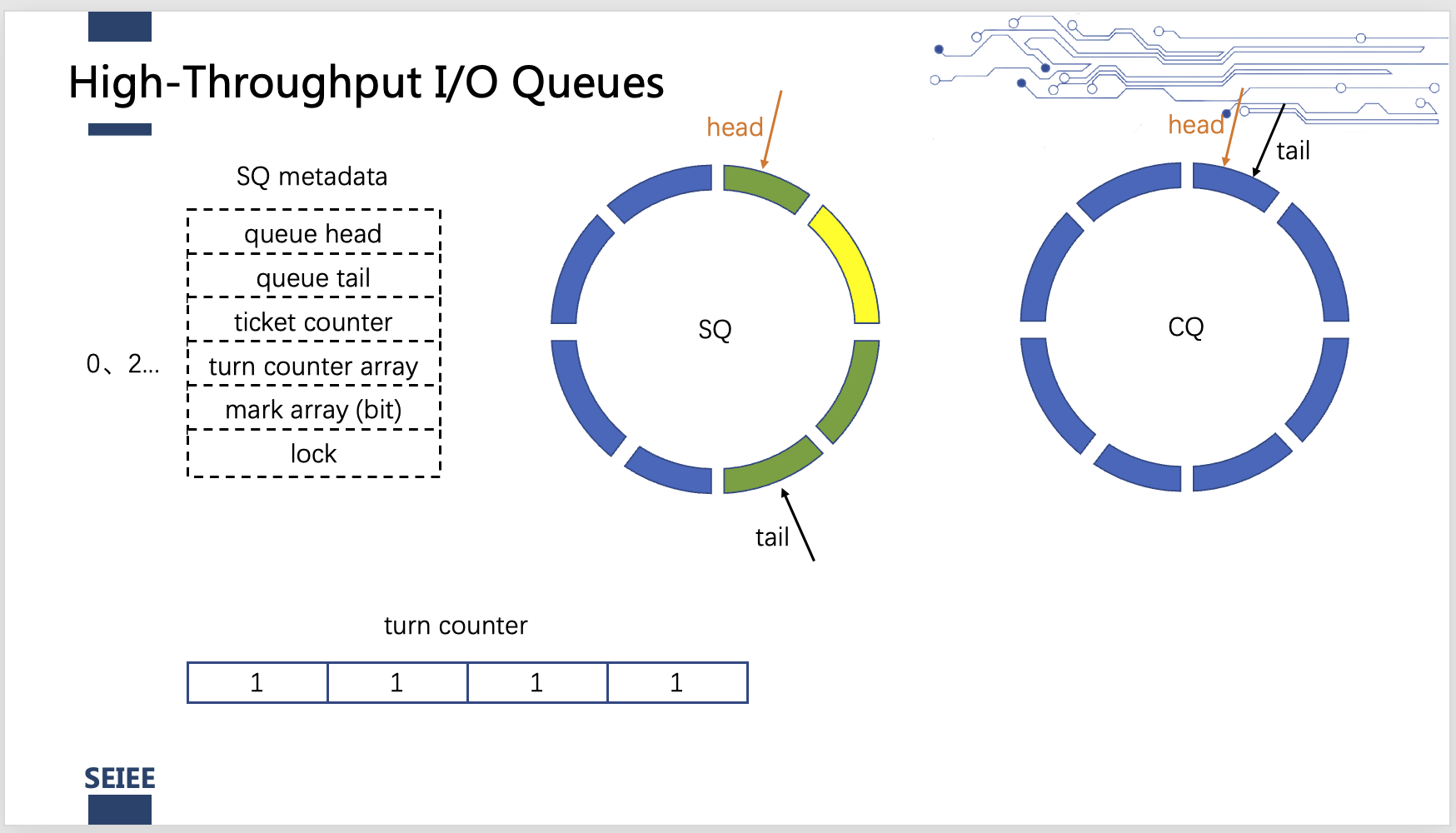
我们以SQ的设计为例说明细粒度的内存同步为何可以实现上述机制并充分利用带宽. BaM系统中可以有多个SQ, CQ队列分别用于不同的SSD. 对于每个SQ, BaM在内存中保留了它的一些元数据:队列的头尾, ticket counter, turn_conter数组, mark位数组, 和一个锁. 其中两个数组的长度都和队列的长度相同.
|
||
|
||
当一个线程要将自己的数据获取请求入队时, 线程需要先将ticket counter的值加1. 此时ticket counter的值为一个长度为2^32的虚拟队列的下标. 用ticket counter与物理队列的长度相除, 余数entry为该线程可以将信号放入物理队列中的哪一项, 商乘2为turn的值, 同时设定队列中该项有效. 线程根据自己的entry轮询turn_counter数组中的对应项查看其对应的值是否与turn相同, 就是不断询问是否轮到自己. 如果轮到这个线程了, 线程就把自己需要执行的I/O操作指令写入到对应的物理队列的entry项中, 同时设定mark对应位. 设定完mark后, 尝试获取这个SQ队列的锁, 获取到锁的线程将SQ tail指针挪到从当前head起始的所有连续的已经设定了mark位的队列项的末尾. 同时将经过的项的mark位重置. 然后发送doorbell信号给存储控制器, 这样就实现了将多个线程的doorbell操作结合. 其他线程如果发现自己的mark位已经被重置,就不再竞争锁, 同时将自己对应位置的turn_conter加1.
|
||
|
||
|
||
|
||
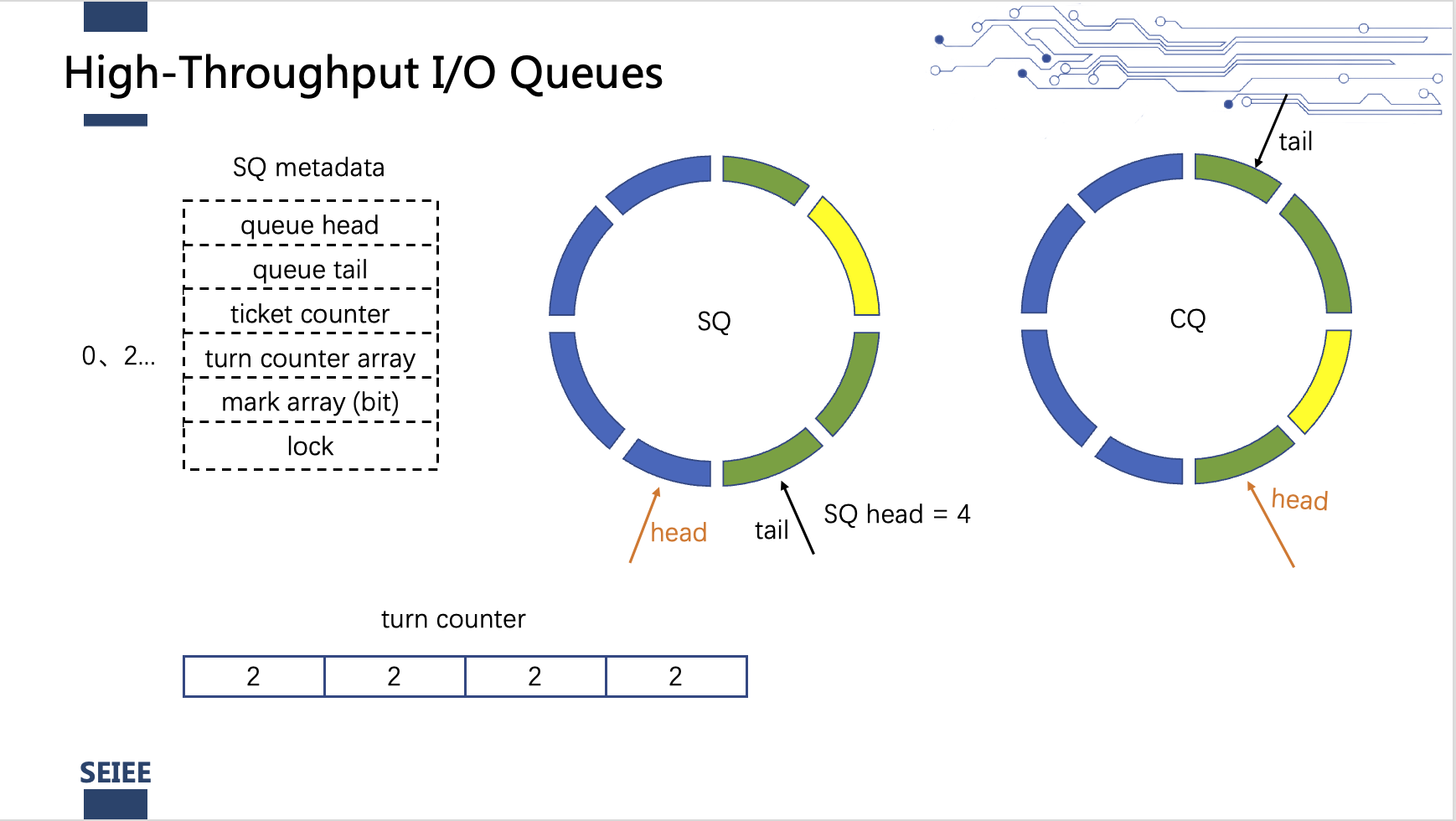
存储器处理完数据请求后, 写入对应CQ中的项, 同时写一个新的SQ head的位置也写在这些项中(同一批处理的请求对应的SQ head应该是相同的). 线程在不断轮询CQ队列查看自己提交的数据请求是否完成, 如果完成就将对应CQ项的mark置位, 竞争锁, 竞争到锁的线程从当前的CQ head开始将所有置位的连续CQ项mark复位, 将head移到这些项的最后一项, 发送doorbell信号表示完成, 同时读取最后一项的SQ head内容, 将SQ队列的head移到从CQ中读到的SQ head所在的位置, 将经过的SQ中的项的turn_counter加1, 此时turn_counter就为偶数, 可以处理下一轮的数据请求.
|
||
|
||
|
||
|
||
## BaM cache设计
|
||
|
||
如果一个线程探测某个偏移处的cache line, 如果这个cache line现在不在cache中, 则锁定该cache line , 并从主存也就是SSD中调取数据, 取到数据后解锁, 在锁定过程中, 所有其他也需要这个偏移处数据的线程都等待这个线程取数据操作完成, 这些线程一起读这个cache line. 这样就节省了频繁的向SSD请求数据.
|
||
|
||
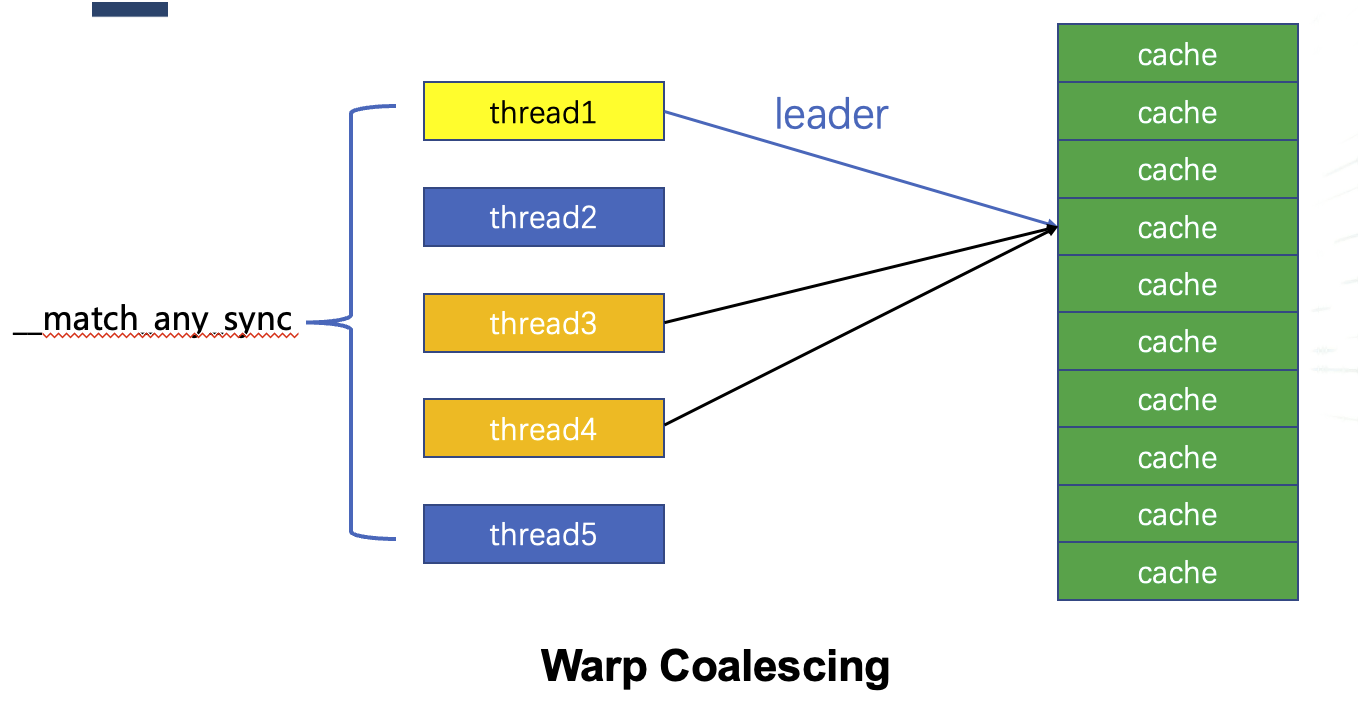
同一个warp中的线程可能会访问内存中的连续字节, 如果这些字节在同一个cache line中, 则会产生竞争来竞争读取该cache line. 如果需要读取的cache line已经在GPU显存中, 这一竞争会产生很大的性能损失. BaM实现了一个\_\_match_any_sync的warp同步原语, 他可以让warp中的线程在访问数据时知道是否有其他线程也在访问同一偏移的数据. 将这些访问同一偏移数据的线程组成一个组, 组中派一个leader线程查询cache并控制需要读取的cache line的状态, 然后leader线程将需要的内存地址广播给组内的所有线程.
|
||
|
||
|
||
|
||
## BaM API
|
||
|
||
BaM在顶层提供给程序员一个高级抽象的数组类型API, bam::array<T>, 程序员可以直接将其看作和诸如C++模板类中的array相同的数组, 并用其进行编程. 无须考虑底层结构.
|
||
|
||
## 性能比较
|
||
|
||
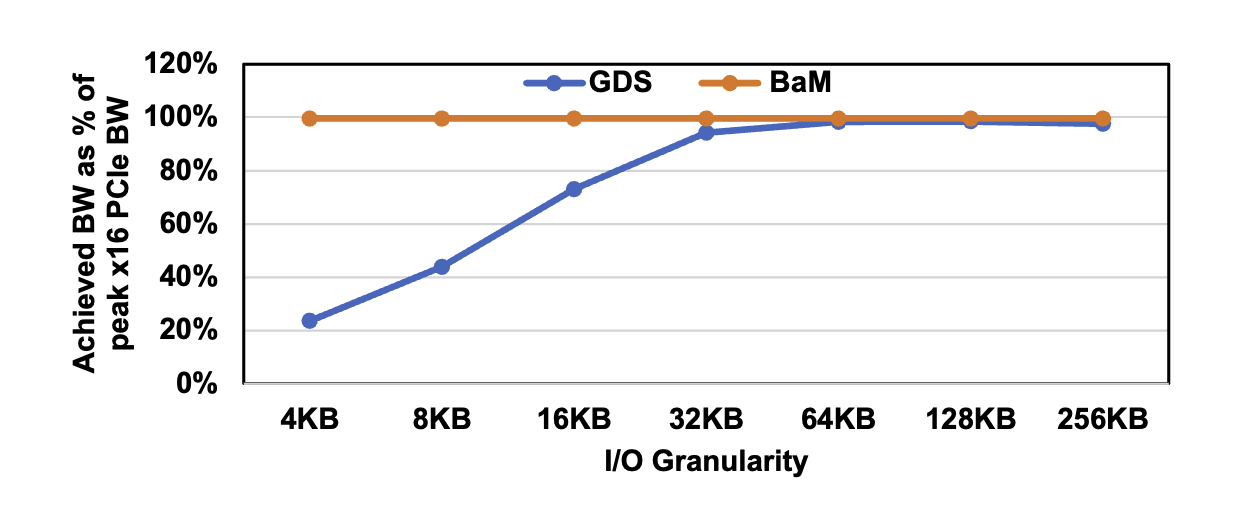
Nvidia在之前推出了GPU Direct Storage, 同样是GPU 直接访问SSD存储, 并且已经在cuda中可用, BaM相对于GDS, 性能上有什么优势呢.
|
||
|
||
|
||
|
||
可见GDS 只能在32KB的大型 I/O 粒度下充分利用GPU的PCIe链路,并且在4KB时仅能达到PCIe带宽的23.6%。相比之下,BaM使用四个SSD就轻松实现了25GBps的带宽,这是测量得到的GPU PCIe链路的峰值带宽。
|
||
|
||
其余性能比较细节可参阅原文中的Evaluation部分. 论文链接: [BaM](https://arxiv.org/abs/2203.04910)
|
||
|
||
## 总结
|
||
|
||
在这项工作中,提出了一种新的系统架构,名为BaM,旨在使 GPU 能够协调高吞吐量、细粒度的存储访问,而无需 CPU 软件的开销。通过允许 GPU 应用程序计算代码根据需求以更细的粒度读取或写入数据,BaM减少了 I/O 过程的性能开销。由于 BaM 支持 GPU 上的存储访问控制平面功能,包括缓存、转换和协议队列,它避免了昂贵的 CPU-GPU 同步、操作系统内核切换和限制可实现存储访问吞吐量的软件瓶颈。使用现成的硬件组件,我们构建了一个 BaM 原型,并在多个应用程序和数据集上展示了 BaM 是一种可行的/优越的替代方案,相比仅使用 DRAM 和其他最先进的解决方案。
|