18 KiB
| title | author | date | categories | tags | draft | |
|---|---|---|---|---|---|---|
| 运维笔记 | Logic | 2025-01-15 | false |
k8s 入门
安装minikube.略
安装kubectl, ubuntu直接使用snap即可. 方便快捷
minikube start 镜像拉取问题,
k8s secret 及 helm chart问题
在 Kubernetes 的 Secret 资源中,data 字段下的每个键(key)对应的值都应该是 整个内容 的 base64 编码,而不是对内容的每个部分分别进行 base64 编码。
如以下的helm chart中定义的secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: {{ include "rag-with-es.fullname" . }}-rag-config
labels:
{{- include "rag-with-es.labels" . | nindent 4 }}
type: Opaque
data:
config.yaml: |
{{- with .Values.rag.config }}
ES_HOST: {{ printf "http://%s-es-svc:%d" (include "rag-with-es.fullname" $) $.Values.es.service.port | b64enc }}
ES_USER: {{ .esUser | b64enc }}
ES_PASSWORD: {{ $.Values.es.config.elasticPassword | b64enc }}
ES_INDEX: {{ .esIndex | b64enc }}
EMBEDDING_API_BASE: {{ .embeddingApiBase | b64enc }}
EMBEDDING_API_KEY: {{ .embeddingApiKey | b64enc }}
EMBEDDING_API_MODEL: {{ .embeddingApiModel | b64enc }}
RERANKER_API_BASE: {{ .rerankerApiBase | b64enc }}
RERANKER_API_KEY: {{ .rerankerApiKey | b64enc }}
RERANKER_API_MODEL: {{ .rerankerApiModel | b64enc }}
{{- end }}
这个secret文件如果使用helm 部署时会显示base64解码错误,错误原因就在于config.yaml对应的值应该是一个完整的base64字符串,而当前的形式会导致仅ES_HOST等键对应的值被编码,ES_HOST等还是明文,故不能正常进行base64解析。正确的做法应为在_helper.tbl中预定义config.yaml对应的模板然后将整个模板作为一个整体用base64编码,如下
// _helper.tbl
{{/*
生成 config.yaml 的内容
*/}}
{{- define "rag-with-es.config" -}}
{{- with .Values.rag.config }}
ES_HOST: {{ printf "http://%s-es-svc:%d" (include "rag-with-es.fullname" $) $.Values.es.service.port }}
ES_USER: {{ .esUser }}
ES_PASSWORD: {{ $.Values.es.config.elasticPassword }}
ES_INDEX: {{ .esIndex }}
EMBEDDING_API_BASE: {{ .embeddingApiBase }}
EMBEDDING_API_KEY: {{ .embeddingApiKey }}
EMBEDDING_API_MODEL: {{ .embeddingApiModel }}
RERANKER_API_BASE: {{ .rerankerApiBase }}
RERANKER_API_KEY: {{ .rerankerApiKey }}
RERANKER_API_MODEL: {{ .rerankerApiModel }}
{{- end }}
{{- end -}}
apiVersion: v1
kind: Secret
metadata:
name: {{ include "rag-with-es.fullname" . }}-rag-config
labels:
{{- include "rag-with-es.labels" . | nindent 4 }}
type: Opaque
data:
config.yaml: {{ include "rag-with-es.config" . | b64enc }}
这样即可正常使用helm部署。
另外可以将secret定义中的data改为使用stringData。stringData 是 Kubernetes Secret 资源中的一个可选字段,它允许用户以明文字符串的形式直接提供 Secret 数据,而不需要像 data 字段那样使用 Base64 编码。
当 Secret 被创建或更新时,stringData 中的内容会自动被转换为 Base64 编码, 转换后的内容会存储在 data 字段中,当读取 Secret 时,只能看到 data 字段,stringData 不会出现在 GET 操作的结果中。不需要手动进行 Base64 编码,特别适合在配置文件中直接写入明文值,对于包含多行内容的配置文件特别有用
apiVersion: v1
kind: Secret
metadata:
name: mysecret
data:
username: YWRtaW4= # Base64 编码
stringData:
config.yaml: | # 多行配置
apiUrl: "https://api.example.com"
timeout: 3000
retries: 5
k8s 主节点安装及启动
- 安装docker和containerd
如果使用apt包管理器方法安装,安装后会同时安装docker和containerd。无需再额外安装containerd运行时。
- 配置cgroup驱动
cgroup 驱动是用来管理和组织 Linux 系统中的 cgroups(控制组)的接口。ubuntu中默认使用systemd作为初始化系统,而当当某个 Linux 系统发行版使用 systemd 作为其初始化系统时,初始化进程会生成并使用一个 root 控制组(cgroup),并充当 cgroup 管理器。则要将systemd配置为容器运行时的cgroup系统。
- 生成默认配置文件
sudo containerd config default | sudo tee /etc/containerd/config.toml
- 编辑配置文件
sudo vim /etc/containerd/config.toml
- 找到runc部分并修改(通常在中间位置)
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
- 重启containerd服务并检查
sudo systemctl restart containerd
sudo crictl info | grep -i cgroup
此时应该能看到SystemdCgroup: true这样的输出
- 临时关闭swap
Kubernetes 默认不支持启用 swap 的节点,因此在启用swap的节点上kubelet无法正常启动,可以临时关闭swap后继续集群的初始化操作。
sudo swapoff -a
- 配置容器镜像
如果不配置容器镜像会导致不能拉取成功从而无法正常启动控制节点,离线情况下要将镜像提前下载好,可以使用如下方式
# 查看需要的镜像
kubeadm config images list
# 拉取镜像
kubeadm config images pull
# 将镜像保存为tar文件
docker save -o k8s-images.tar $(kubeadm config images list)
在需要的机器上加载镜像
# 在离线环境中加载镜像
docker load -i k8s-images.tar
而在可以连接网络的情况下,可以设置containerd的镜像地址,修改containerd的配置文件config.toml
# 其他配置...
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = ""
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://hub.rat.dev"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"]
endpoint = ["https://registry.aliyuncs.com/google_containers"]
- 使用kubeadm 初始化集群
# 初始化集群控制台 Control plane,保险起见此处也加上镜像地址
# 失败了可以用 kubeadm reset 重置
# 此命令某些情况下可行
kubeadm init --image-repository=registry.aliyuncs.com/google_containers
# 在使用flannel的情况下应该添加下面这条命令中的参数
kubeadm init --image-repository=registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16
失败需要将集群重置,可参考移除节点。
kubeadm reset
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
ipvsadm -C
注意此处限于刚启动集群中没有其他工作负载的情况,有工作负载则要先清空节点负载,再重置。
- 完成初始化工作并安装pod网络附加组件(
根据控制台给出的提示
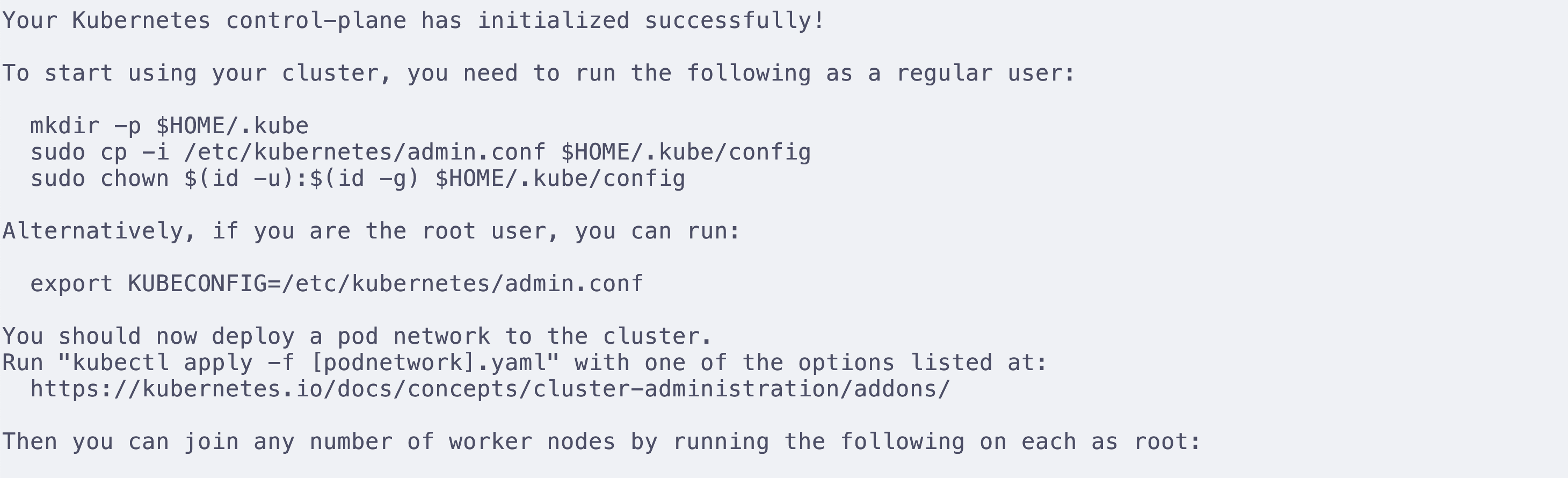
先设定kubeconfig,kubeconfig可以告诉kubectl在哪里找到集群的配置信息,从而让kubectl能够成功控制集群,其中包含访问k8s集群需要的认证信息。
非root用户使用
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
root用户使用
export KUBECONFIG=/etc/kubernetes/admin.conf
安装pod网络附加组件,可用的组件列表,这里安装比较常用的flannel。安装网络组件后pod网络之间才能互通,coreDNS才会启动。
可使用kubectl或者helm安装,这里使用kubectl安装
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
注意github可能不能访问,可以直接将这个yml下载下来并保存到主机上,随后将apply的文件替换为本地文件即可,注意flannel拉取的仓库是ghcr.io即github的包管理地址,因此也要将这个地址设置镜像地址,可以使用
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."ghcr.io"]
endpoint = ["https://docker.imgdb.de/ghcr.io"]
此处使用该方法启动flannel失败,显示不能获取控制平面节点的CIDR,参阅初始化控制平面节点可知,使用一些第三方网络插件时可能需要设置--pod-network-cidr,因此要重置集群并重新init并加入--pod-network-cidr参数,如下
kubeadm init --image-repository=registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16
再重新启动flannel,至此集群初始化全部完成,已经可以运行负载
如果想要在该控制平面机器上调度其他pod,则要通过下面的命令将从任何拥有 node-role.kubernetes.io/control-plane:NoSchedule 污点的节点(包括控制平面节点)上移除该污点。 这意味着调度程序将能够在任何地方调度 Pod。可参考控制平面节点隔离
kubectl taint nodes --all node-role.kubernetes.io/control-plane
修复不同节点使用内网ip不互通的问题(异地组网)
修改master节点flannel配置文件
共修改两个地方,一个是args下,添加
args:
- --public-ip=$(PUBLIC_IP) # 添加此参数,申明公网IP
- --iface=eth0 # 添加此参数,绑定网卡
然后是env下
env:
- name: PUBLIC_IP #添加环境变量
valueFrom:
fieldRef:
fieldPath: status.podIP
尝试不同节点下的pod ping 失败
使用iptables重定向ip
把内网 IP 192.168.0.111 转向外网 IP 123.123.123.123
$ iptables -t nat -A OUTPUT -d 192.168.0.111 -j DNAT --to-destination 123.123.123.123
尝试将master节点和4090节点的内网IP均转为对方的公网IP。设置好iptables后4090可以ping通master的内网IP,但master不能ping通4090. 因为使用其他电脑也不能ping通4090,可能是4090的ping被禁止相应。尝试使用在master下的pod ping 4090的pod。失败
配置Raven
$ cat <<EOF | kubectl apply -f -
apiVersion: raven.openyurt.io/v1beta1
kind: Gateway
metadata:
name: gw-edge
spec:
tunnelConfig:
Replicas: 1
endpoints:
- nodeName: 4090
underNAT: true
port: 31998
type: tunnel
EOF
使用zerotier-one构建虚拟子网
使用zerotier-one在master和4090之间构建一个虚拟子网,并在添加边缘节点时指定nodeIface参数使得flannel和kubelet使用构建好虚拟子网后的4090上的虚拟网卡获取ip,这个ip位于虚拟子网中,从master节点可以直接ping通。
节点的flannel是如何指定使用哪个网卡的呢,查看k8s守护进程集中的kube-flannel,可以发现其启动执行命令为
["/bin/sh","-c","set -x\n\nif [ -e /etc/kubernetes/flannel/iface ]; then\n IFACE=`cat /etc/kubernetes/flannel/iface`\nfi\n\n/opt/bin/flanneld --ip-masq --kube-subnet-mgr --iface=$IFACE\n"]
其中iface参数制订了flannel使用的具体网卡,而这个参数可以通过/etc/kubernetes/flannel/iface设定,如果没有这个文件创建这个文件并向其中写入网卡名。
除此之外,对于使用vxlan模式的flannel,其vxlan构建时默认使用8472端口并使用UDP协议,而4090机器上只开放了31000-31999端口,因此可以在configmap中找到kube-flannel-cfg并修改其中的net-conf.json,修改后端backend添加配置Port并指定端口为31999端口,注意master主机的安全组中也要放行这个端口(UDP协议)。
// net-conf.json
{
"Network": "10.61.0.0/16",
"Backend": {
"Type": "vxlan",
"Port": 31999
}
}
使用zerotier-one的过程比较简单,可以自建zerotier-one的服务,参考如下仓库
https://github.com/xubiaolin/docker-zerotier-planet
组网即可
其实zerotier-one底层也是使用wireguard,而raven和yurt-manager同样也可以使用wireguard,但默认是ipsec并且其默认的4500端口在4090上并未开放,因此主要问题就出现在端口未开放上。
阿里云VPN接入VPC
根据文档说明一步步操作。到步骤四,步骤四中给出的示例是使用思科防火墙的示例,在单机状态下当然不需要这个配置。可以使用strongswan配置vpn。找到strongswan配置的文档,阿里云使用的是swanctl来配置,而当前ubuntu apt安装的包默认使用starter和charon。因此根据文档
When installing the strongswan metapackage, the legacy daemon and configuration backend are installed. To use swanctl/vici instead, install the charon-systemd and strongswan-swanctl packages and remove both the strongswan-starter and strongswan-charon packages. Make sure you only have either the charon-systemd or the strongswan-starter package installed (or at least disable one of the systemd units they install, which are strongswan.service and strongswan-starter.service, respectively).
sudo apt remove strongswan-starter
sudo apt remove strongswan-charon
sudo apt install charon-systemd
sudo apt install strongswan-swanctl
安装swanctl后,根据strongSwan配置示例
注意这里有个坑点,安装swanctl后配置好swanctl的conf配置文件,连接阿里云的vpn连接不上,最后发现在双隧道模式下如果使用strongswan连接到同一台机器上,配置的双隧道的各项配置需要完全一样(密钥除外)。这样按照文档才能连接上,如果两个隧道某项配置不一样,就会出现密钥协商失败。
另外注意,如果配置的双隧道,则设置路由的时候一定要让本地机器去往vpc的ip的路由走主隧道对应的虚拟接口,如果走副隧道对应的虚拟接口会出现尽管本地机器可以Ping通vpn对应的ip,但vpc网络下的ecs无法ping通本地主机的情况。这里阿里云工程师给的解释如下

手动配置wireguard端到端连接
写好wireguard配置文件后使用wg-quick启动连接。
写一个监视脚本在服务出现问题时自动重启wireguard
#!/bin/bash
# 日志文件路径
LOG_FILE="/var/log/wg_monitor.log"
# 网站 URL
WEBSITE="https://poc-jinshu.truth-ai.com.cn"
# 记录日志的函数
log() {
echo "$(date '+%Y-%m-%d %H:%M:%S') - $1" >> "$LOG_FILE"
}
# 重启 WireGuard 的函数
restart_wireguard() {
log "正在重启 WireGuard..."
# 请根据您的系统配置修改以下命令
sudo wg-quick down wg0 && sudo wg-quick up wg0
log "WireGuard 已重启"
}
# 检查 wg0 接口状态
if ! ip link show wg0 &> /dev/null; then
log "wg0 接口不存在,正在重启 WireGuard..."
restart_wireguard
fi
# 检查 WireGuard 连接状态
if ! sudo wg show wg0 &> /dev/null; then
log "WireGuard 连接异常,正在重启..."
restart_wireguard
fi
# 检查网站状态
HTTP_STATUS=$(curl -s -o /dev/null -w "%{http_code}" "$WEBSITE")
if [ "$HTTP_STATUS" = "504" ]; then
log "网站返回 504 错误,正在重启 WireGuard..."
restart_wireguard
fi
echo "all normal"
使用crontab配置该脚本每3分钟自动运行一次,在crontab中添加以下配置
*/3 * * * * path/to/shellscript
ingress-nginx-controller
Warning
ingress-nginx和nginx-ingress不相同,是两个不同的项目,对应的配置项自然也不同,阿里云k8s中使用的都是k8s社区自己维护的ingress-nginx,nginx-ingress由nginx社区维护。使用时要加以区分。
ingress nginx controller本质上仍然是nginx,因此许多配置也是基于此展开的,可以和nginx的配置结合起来理解。
启动nginx-ingress-controller时需要增加启动参数以启用snippets功能, 查询ingress-nginx的文档,可以看到ingress-nginx的configmap中可配置的项和说明,本质上仍然是nginx,所以像stream-snippet和http-snippet和server-snippet这样的配置项的含义需要和nginx中的配置模块对应起来。而在这里要做的是增加一个响应头,因在所有响应中都加入一个响应头,故用configmap中的location-snippet项,其对应的是nginx中的location块,向这个配置中写入代码等于向nginx中location块插入的配置代码。在响应中增加一个响应头表示request-id,用于跟踪每个响应的状态。插入的nginx配置代码如下
more_set_headers "Request-Id: $request_id";
这里request_id变量在ingress-nginx中可通过设定配置项生成,设定generate-request-id项为true即可自动生成request_id。
docker一键安装脚本及使用镜像
安装docker
docker官方提供了傻瓜式安装脚本,为你做好所有工作,免去了手动安装的繁琐。
注意是 docker compose 而不是 docker-compose. 执行命令时候也没有这个杠
curl -fsSL https://get.docker.com | bash -s docker
可在此命令后附带--mirror参数设置镜像源,以提高国内服务器下载docker的速度
如使用阿里云镜像:
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
k3s 入门手册
安装k3s
K3s 提供了一个安装脚本,可以方便地将其作为服务安装在基于 systemd 或 openrc 的系统上。该脚本可在 https://get.k3s.io 获得。要使用这种方法安装 K3s,只需运行:
curl -sfL https://get.k3s.io | sh -
备注 中国用户,可以使用以下方法加速安装:
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL
配置k3s镜像拉取镜像
参考 k3s镜像配置
可供参考的registries.yaml为
mirrors:
docker.io:
endpoint:
- "docker-0.unsee.tech"
- "docker.1panel.live"
- "hub.fast360.xyz"