# DDT: Decoupled Diffusion Transformer
## Introduction
We decouple diffusion transformer into encoder-decoder design, and surpresingly that a **more substantial encoder yields performance improvements as model size increases**.
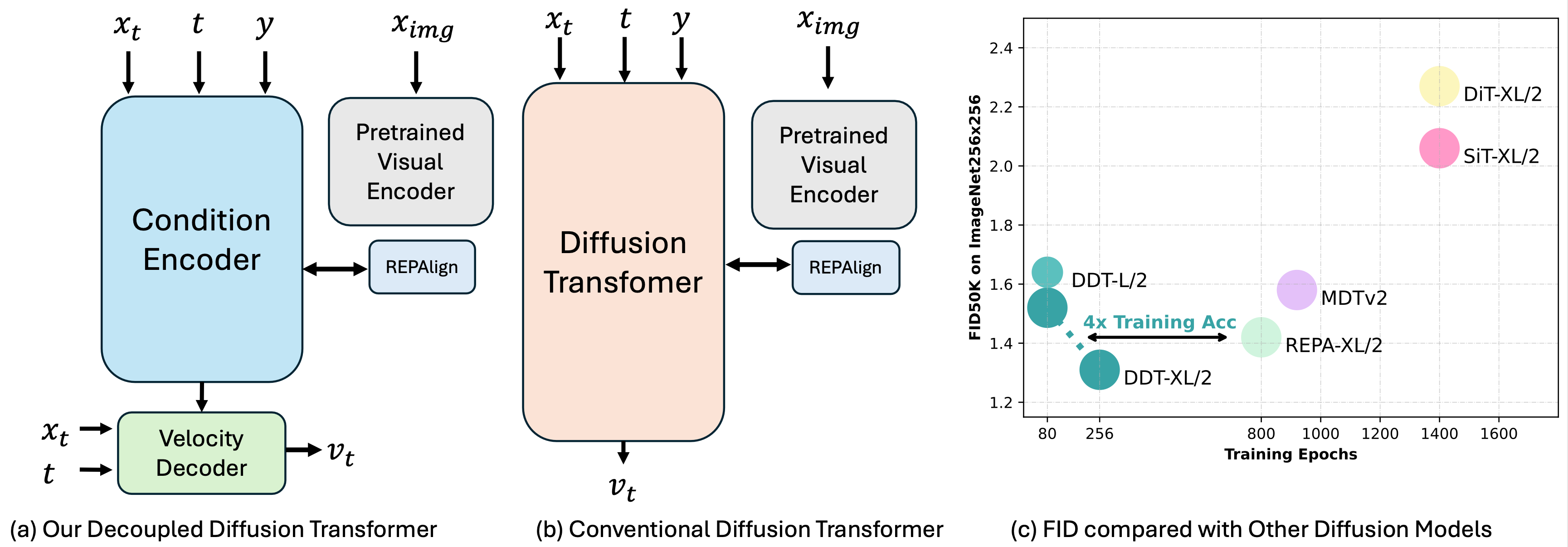
* We achieves **1.26 FID** on ImageNet256x256 Benchmark with DDT-XL/2(22en6de).
* We achieves **1.28 FID** on ImageNet512x512 Benchmark with DDT-XL/2(22en6de).
* As a byproduct, our DDT can reuse encoder among adjacent steps to accelerate inference.
## Visualizations

## Checkpoints
We take the off-shelf [VAE](https://huggingface.co/stabilityai/sd-vae-ft-ema) to encode image into latent space, and train the decoder with DDT.
| Dataset | Model | Params | FID | HuggingFace |
|-------------|-------------------|-----------|------|----------------------------------------------------------|
| ImageNet256 | DDT-XL/2(22en6de) | 675M | 1.26 | [🤗](https://huggingface.co/MCG-NJU/DDT-XL-22en6de-R256) |
| ImageNet512 | DDT-XL/2(22en6de) | 675M | 1.28 | [🤗](https://huggingface.co/MCG-NJU/DDT-XL-22en6de-R512) |
## Online Demos
We provide online demos for DDT-XL/2(22en6de) on HuggingFace Spaces.
HF spases: [https://huggingface.co/spaces/MCG-NJU/DDT](https://huggingface.co/spaces/MCG-NJU/DDT)
## Usages
We use ADM evaluation suite to report FID.
```bash
# for installation
pip install -r requirements.txt
```
By default, the `main.py` will use all available GPUs. You can specify the GPU(s) to use with `CUDA_VISIBLE_DEVICES`.
or specify the number of GPUs to use with as :
```yaml
# in configs/repa_improved_ddt_xlen22de6_256.yaml
trainer:
default_root_dir: universal_flow_workdirs
accelerator: auto
strategy: auto
devices: auto
# devices: 0,
# devices: 0,1
num_nodes: 1
```
By default, the `save_image_callbacks` will only save the first 100 images and npz file(to calculate FID with ADM suite). You can change the number of images to save with as :
```yaml
# in configs/repa_improved_ddt_xlen22de6_256.yaml
callbacks:
- class_path: src.callbacks.model_checkpoint.CheckpointHook
init_args:
every_n_train_steps: 10000
save_top_k: -1
save_last: true
- class_path: src.callbacks.save_images.SaveImagesHook
init_args:
save_dir: val
max_save_num: 0
# max_save_num: 100
```
```bash
# for inference
python main.py predict -c configs/repa_improved_ddt_xlen22de6_256.yaml --ckpt_path=XXX.ckpt
```
```bash
# for training
# extract image latent (optional)
python3 tools/cache_imlatent4.py
# train
python main.py fit -c configs/repa_improved_ddt_xlen22de6_256.yaml
```
## Reference
```bibtex
@article{wang2025ddt,
title={DDT: Decoupled Diffusion Transformer},
author={Wang, Shuai and Tian, Zhi and Huang, Weilin and Wang, Limin},
journal={arXiv preprint arXiv:2504.05741},
year={2025}
}
```
## Acknowledgement
The code is mainly built upon [FlowDCN](https://github.com/MCG-NJU/FlowDCN), we also borrow ideas from the [REPA](https://github.com/sihyun-yu/REPA), [MAR](https://github.com/LTH14/mar) and [SiT](https://github.com/willisma/SiT).